How to Scrape Monster Job Posting Data using Python
How to Scrape Monster Job Posting Data using Python
Send download link to:
Monsterjob.com is world’s leading online job portal. It lists millions of jobs on its website and app all around the world. One can create a complete profile here with all educational details, work experience, resume etc. and reach out to potential employers. Hiring managers use monster to find the right candidates from millions of profiles available here. So to scrape Monster data provide automate way to extract bulk data.
Finding the right match for a job, or a candidate may be cumbersome given the score of options available. This can be automated and handled with ease with web scraping. You can search for a job using keywords, scrape all the details and then filter them out as per your profile. Similarly for a hiring manager instead of going one by one to all profiles just scrape Monster data and put filters to find right candidates. Not only that one can also look for what are all the skills in demand for a particular kind of job, do data analysis and learn the most relevant skills. So there are lot of advantages of scraping a job site.
In this tutorial we will go to monster job website and search for software developer jobs in Australia
https://www.monster.com/jobs/search/?q=Software-Developer&where=Australia&cy=AU
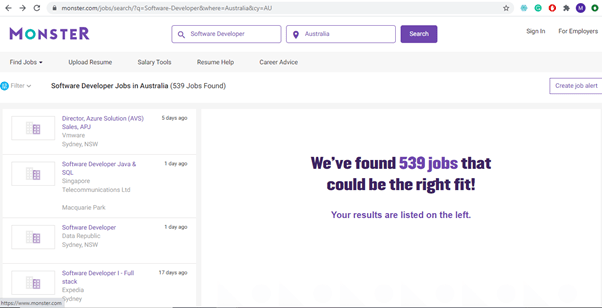
We will scrape the details like job title, company name, location and then scrape complete job description.
See the complete code below or watch video for detailed explanation:
Import libraries:
import requests
from bs4 import BeautifulSoup as soup
Send get request:
URL = 'https://www.monster.com/jobs/search/?q=Software-Developer&where=Australia&cy=AU'
page = requests.get(URL)
Get Job title:
title = []
for header in bsobj.findAll('h2',{'class':'title'}):
title.append(header.text.strip())
title
Output:

Get Company name:
company = []
for name in bsobj.findAll('div',{'class':'company'}):
company.append(name.text.strip())
company
Output:

Get Location:
location = []
for locs in bsobj.findAll('div',{'class':'location'}):
location.append(locs.text.strip())
location = location[1:]
location
Output:

Create pandas data frame:
import pandas as pd
d1 = {'title':title,'company':company,'location':location}
df = pd.DataFrame.from_dict(d1)
Output:

Get complete Job description:
links = []
for link in bsobj.findAll('h2',{'class':'title'}):
links.append(link.a['href'])
for link in links:
html = requests.get(link)
#print(html.status_code)
bs = soup(html.content,'lxml')
for a in bs.findAll('div',{'class':'col-md-8'}):
print(a.text.strip())
Output:
Further more understand about our Monster data scraping services and how job posting data can help you. Also download sample data for clear vision about data and which field can be extracted from that.