Intriduction to Scrapy & How Scrapy Works
Scrapy is a Python framework for large scale web scraping. It gives you all the tools you need to efficiently extract data from websites, process them as you want, and store them in your preferred structure and format.
Scrapy uses spiders, which are self-contained crawlers that are given a set of instructions. In Scrapy it is easier to build and scale large crawling projects by allowing developers to reuse their code.
How Scrapy Works

Spider is the element which contains the main script for scraping. It sends a request to engine which in turn sends this request to a scheduler. The Scheduler’s function is to check for any pending request and send back those requests to engine based on priority. The Engine sends request received from scheduler to downloader, which then connects to the webpage. It downloads the html response and sends back response to the engine. Finally, the engine sends response received to spider for verification and then to item pipeline which extract and stores the required data.
Default Structure of Scrapy Project
The following structure shows the default file structure of the Scrapy project. Although it can be modified as per user requirement.
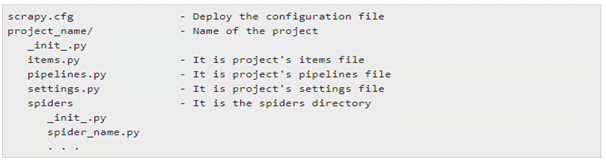
Now let’s see the elements of scrapy in details:
Spiders
Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items).In other words, Spiders are the place where you define the custom behaviour for crawling and parsing pages for a particular site (or, in some cases, a group of sites).
Selectors
When you are scraping the web pages, you need to extract a certain part of the HTML source by using the mechanism called selectors, this is achieved by using either XPath or CSS expressions. Selectors are built upon the lxml library, which processes the XML and HTML in Python language.
Items
Scrapy process can be used to extract the data from sources such as web pages using the spiders. Scrapy uses Item class to produce the output whose objects are used to gather the scraped data.
Item Fields
The item fields are used to display the metadata for each field. As there is no limitation of values on the field objects, the accessible metadata keys does not contain any reference list of the metadata. The field objects are used to specify all the field metadata. You can specify any other field key as per your requirement in the project. The field objects can be accessed using the Item.fields attribute.
Shell
Scrapy shell can be used to scrap the data with error free code, without the use of spider. The main purpose of Scrapy shell is to test the extracted code, XPath, or CSS expressions. It also helps specify the web pages from which you are scraping the data.
Item Pipeline
Item Pipeline is a method where the scrapped items are processed. When an item is sent to the Item Pipeline, it is scraped by a spider and processed using several components, which are executed sequentially.
Whenever an item is received, it decides either of the following action −
- Keep processing the item.
- Drop it from pipeline.
- Stop processing the item.
Item pipelines are generally used for the following purposes −
- Storing scraped items in database.
- If the received item is repeated, then it will drop the repeated item.
- It will check whether the item is with targeted fields.
- Clearing HTML data.
Feed Exports
Feed exports is a method of storing the data scraped from the sites, that is generating a “export file”.
Request and Response:
Scrapy can crawl websites using the Request and Response objects. The request objects pass over the system, uses the spiders to execute the request and get back to the request when it returns a response object.
Link Extractors
As the name itself indicates, Link Extractors are the objects that are used to extract links from web pages using scrapy.http.Response objects. In Scrapy, there are built-in extractors such as scrapy.linkextractors import LinkExtractor. You can customize your own link extractor according to your needs by implementing a simple interface.
Features of Scrapy
- Scrapy is an open source and free to use web crawling framework.
- Scrapy generates feed exports in formats such as JSON, CSV, and XML.
- Scrapy has built-in support for selecting and extracting data from sources either by XPath or CSS expressions.
- Scrapy based on crawler, allows extracting data from the web pages automatically.
Advantages
- Scrapy is easily extensible, fast, and powerful.
- It is a cross-platform application framework (Windows, Linux, Mac OS and BSD).
- Scrapy requests are scheduled and processed asynchronously.
- Scrapy comes with built-in service called Scrapyd which allows to upload projects and control spiders using JSON web service.
- It is possible to scrap any website, though that website does not have API for raw data access.
Scrapy is afull-fledged framework made for web scraping. It can create very powerful crawlers for big data extraction projects. But there is steep learning curve with Scrapy.