Introduction to Beautiful Soup
Beautiful Soup is a Python library for getting data out of HTML, XML, and other mark-up languages. Say you’ve found some webpages that display data relevant to your research, such as product information, name, email etc. but it does not provide any way to download the data directly. Beautiful Soup Python helps you pull particular content from a webpage, remove the HTML mark-up, and save the information. It is a tool for web scraping that helps you clean up and parse the documents you have pulled down from the web.
The Beautiful Soup documentation will give you a sense of variety of things that the Beautiful Soup library will help with, from isolating titles and links, to extracting all of the text from the html tags, even to altering the HTML within the document you’re working with.
Installing and Importing Beautiful Soup
We will now install beautifulsoup4. Prior to BS4, BS3 and BS2 were available. To Install BeautifulSoup do a pip install as below:

Now import beautifulsoup4 as below:

Soup is the common alias used for BS4.
BS4 can extract data from HTML or XML pages. But it cannot make a request to a web page to download the HTML or XML content. To do so we need to use some other libraries like Urllib or request. Here we will use urllib.
To extract data from webpage we first need to inspect it and find under which tags our data is available. To do that first open web page in your browser. In this tutorial we are going to scrape data from IMDB, so we will be going to this page https://www.imdb.com/list/ls068010962/. This page has the list of top 50 Bollywood stars.
Go to this page and then either right click on any data and click on inspect or press ctrl+shift+I to go to developer menu and inspect the elements.
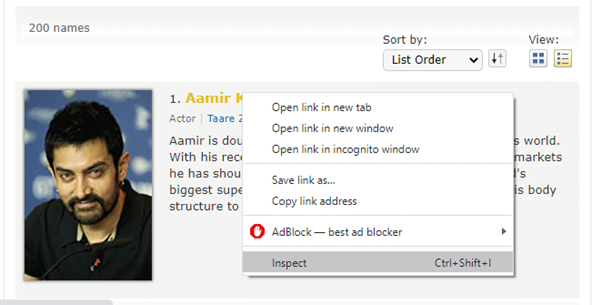
This will open developer options where we can find all the HTML tags and data.
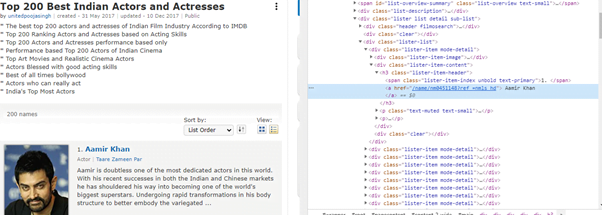
Now we can find the HTML tag of any element on this page and use BS4 to extract data from the tag.
To download this page send a request using urllib and parse the page using BS4 as shown below:

Output:
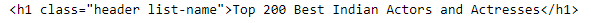
Last line of this code bsobj.h1 gives us the header which is under h1 tag on the page.
In similar way you can find other tags and grab the data using them. BS4 is very useful for data scraping services. Going forward we will learn more ways to grab data using BS4.