Scraping Amazon Reviews using Python
Scraping Amazon Reviews using Python
Send download link to:
In one of our previous tutorial we scraped product data from Amazon like product price, size, colour etc. In this tutorial we will learn scraping Amazon reviews i.e. product reviews by its consumers. Such data is highly sort after for consumer behaviour study and for other analysis.
Review Data offer valuable insights, for example if you have launched your product you can analyse your customer response as to what they like or don’t like, and additional features recommended regarding your product. Sales trajectory from reviews also helps you improve your product and establish your market presence. The key to such insightful data can be unlocked with your simple scraping script.
Scraping Amazon reviews can turn out to be tedious task, if it is not planned in advance, a popular product review may run into thousands of pages.
In this tutorial we will create a script which can be used to scrape review of any product from Amazon buy with just few changes. First we will create a search query and by changing this search query we can go to different products and scrape their reviews. We will go to https://www.amazon.com/s?k=nike+shoes+men and scrape review for all of the shoes listed on this page.

We will use our standard libraries request() and BeautifulSoup to scrape all this data:
import pandas as pd
import requests
from bs4 import BeautifulSoup
Defining search query, by changing this you can serach for any product on amazon:
search_query=”nike+shoes+men”
Creating complete url by adding search query to base url:
base_url=https://www.amazon.com/s?k=
url=base_url+search_query
Output:
‘https://www.amazon.com/s?k=nike+shoes+men’
Define user Agent and send a get request:
header={‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36′,’referer’:’https://www.amazon.com/s?k=nike+shoes+men&crid=28WRS5SFLWWZ6&sprefix=nike%2Caps%2C357&ref=nb_sb_ss_organic-diversity_2_4′}
search_response=requests.get(url,headers=header)
Create a function to get the content of page:
Cookie={} #insert request cookies within{}
def getAmazonSearch(search_query):
url=”https://www.amazon.com/s?k=”+search_query
print(url)
page=requests.get(url,headers=header)
if page.status_code==200:
return page
else:
return “Error”
Create a function to get the contents of individual product pages using ‘data-asin’ number (unique identification number): Data asin number is a unique number for every single product listed on amazon. Using this number and adding to base url we can go to every single product page and scrape data, so this is the main point of all this script.
Below we can see the asin number for a product:

def Searchasin(asin):
url="https://www.amazon.com/dp/"+asin
print(url)
page=requests.get(url,cookies=cookie,headers=header)
if page.status_code==200:
return page
else:
return "Error"
Create a function to pass on the link of ‘see all reviews’ and extract the content: This function will help us to go to all products using asin number and then grab the links for “see all reviews” :
def Searchreviews(review_link):
url="https://www.amazon.com"+review_link
print(url)
page=requests.get(url,cookies=cookie,headers=header)
if page.status_code==200:
return page
else:
return "Error"
Now let’s grab the asin number of all products and save it into a list:
data_asin=[]
response=getAmazonSearch('nike+shoes+men')
soup=BeautifulSoup(response.content)
for a in soup.findAll("div",{'class':"sg-col-4-of-24 sg-col-4-of-12 sg-col-4-of-36 s-result-item s-asin sg-col-4-of-28 sg-col-4-of-16 sg-col sg-col-4-of-20 sg-col-4-of-32"}):
data_asin.append(a['data-asin'])
By passing the data-asin numbers, we can extract the ‘see all reviews’ link for each product in the page:
link=[]
for b in range(len(data_asin)):
response=Searchasin(data_asin[i])
soup=BeautifulSoup(response.content)
for b in soup.findAll("a",{'data-hook':"see-all-reviews-link-foot"}):
link.append(b['href'])
Now we have the ‘see all review’ links. Using this link along with a page number, we can extract the reviews in any number of pages for all the products and save it into a list called reviews[]
reviews=[]
for j in range(len(link)):
for k in range(100):
response=Searchreviews(link[j]+'&pageNumber='+str(k))
soup=BeautifulSoup(response.content)
for i in soup.findAll("span",{'data-hook':"review-body"}):
reviews.append(i.text)
Now that we have got our reviews let’s save it to a pandas data frame:
rev={'reviews':reviews}
review_data=pd.DataFrame.from_dict(rev)
pd.set_option('max_colwidth',800)
review_data.head(5)
Output:
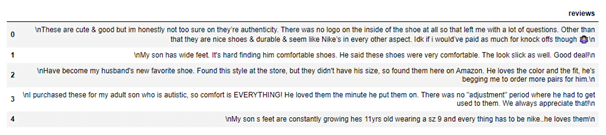
Hope this tutorial is helpful for you. Are you in need of bulk product data from amazon for product analysis without taking headache of coding ? Then we can scrape fresh data for you for further analysis in required format. Download our previously scraped sample data of Amazon data scraper. Even we have experience on daily basis scraping of lakhs of data from Amazon and Aliexpress.