Glassdoor Scraping – Scrape Glassdoor Job Postings using Python
Glassdoor Scraping – Scrape Glassdoor Job Postings using Python
Send download link to:
Glassdoor is a very popular website for Job serach, company reviews, employee reviews, and interview tips for a particular company or profile etc. Millions of users uses glassdoor every year and share their experience of working in a company which helps others to make a good career choice. Also hundreds of jobs are posted daily on glassdoor making it a more preferred website for job seekers as well as recruiters. So, scrape Glassdoor Job Postings is beneficial to collect such listings.
Using web scraping one can find jobs suiting his profile or scrape reviews do a sentiment analysis and decide which company is a great place to work at.
In this tutorial we will scrape job details from glassdoor. We will search for data scientist jobs in Los Angeles. https://www.glassdoor.co.in/Job/los-angeles-data-scientist-jobs-SRCH_IL.0,11_IC1146821_KE12,26.htm .

We will grab details like company name, location, job title ad then grab the links of all jobs and go to each individual page and scrape complete job description.
See complete code below or watch video for detailed description.
Import Libraries
import requests
from bs4 import BeautifulSoup as soup
Set Headers:
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}
Send Get request:
html = requests.get('https://www.glassdoor.co.in/Job/los-angeles-data-scientist-jobs-SRCH_IL.0,11_IC1146821_KE12,26.htm', headers = headers)
bsobj = soup(html.content,'lxml')
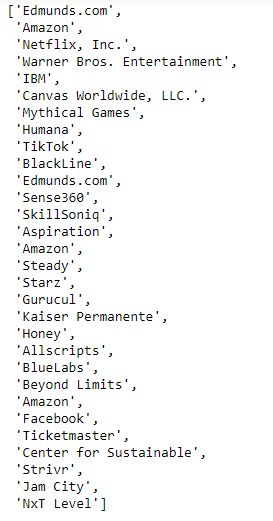
Scrape company name:
company_name =[]
for company in bsobj.findAll('div',{'class':'jobHeader'}):
company_name.append(company.a.text.strip())
company_name
Output:
Scraping Job Title:
job_title = []
for title in bsobj.findAll('div',{'class':'jobContainer'}):
job_title.append(title.findAll('a')[1].text.strip())
job_title
Output:

Scraping Job Location:
location = []
for i in bsobj.findAll('div',{'class':'jobInfoItem empLoc'}):
location.append(i.span.text.strip())
location
Output:

Grab individual job links:
links = []
for i in bsobj.findAll('div',{'class':'jobContainer'}):
link = 'https://www.glassdoor.co.in'+ i.a['href']
links.append(link)
links
Output:

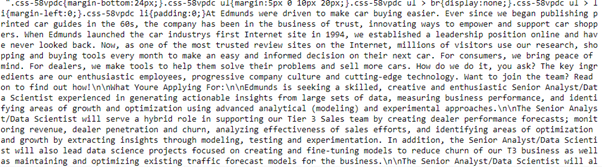
Scrape job description by going to individual links:
description = []
for link in links:
page = requests.get(link,headers=headers)
bs = soup(page.content,'lxml')
for job in bs.findAll('div',{'id':'JobDescriptionContainer'})[0]:
description.append(job.text.strip())
Output:
For bulk data extraction requirement from Glassdoor our scraping services can help you to scrape Glassdoor Job Postings data according to your search criteria. For more insight about data download sample data of Glassdoor scraping.