How to Download Videos from Any Website using Python
How to Download Videos from Any Website using Python
Send download link to:
In one of our previous tutorial we learnt to download videos from YouTube. We used a custom library called pytube3 for it. But what if we want to download videos using python from any other website? We can’t use pytube3 there nor can we have custom libraries for every website.
So to download videos from any website we will have to use our web scrapping libraries BeautifulSoup and Requests. In this tutorial we will learn how we can download videos from any website using our web scraping skills.
We will go to University of Munich’s website and download the videos. This website contains videos as well as some pdf’s and other files, we will only download videos.
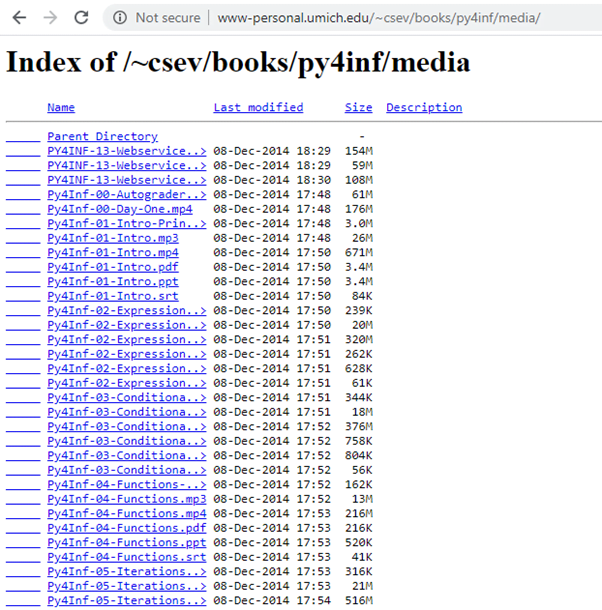
If you notice carefully you can see that all the videos have mp4 extension, which is what we have to look for. Moreover all the files have an embedded link from where they can be downloaded. We can find all these links and then download files:
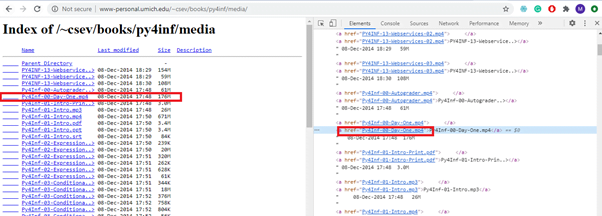
Let’s get to the code:
import requests
from bs4 import BeautifulSoup
# specify the URL of the archive here
archive_url = "http://www-personal.umich.edu/~csev/books/py4inf/media/"
def get_video_links():
#create response object
r = requests.get(archive_url)
#create beautiful-soup object
soup = BeautifulSoup(r.content,'html5lib')
#find all links on web-page
links = soup.findAll('a')
#filter the link ending with .mp4
video_links = [archive_url + link['href'] for link in links if link['href'].endswith('mp4')]
return video_links
Now that we have grabbed the links we can send get request to these links and download videos as below:
def download_video_series(video_links):
for link in video_links:
# iterate through all links in video_links
# and download them one by one
#obtain filename by splitting url and getting last string
file_name = link.split('/')[-1]
print ("Downloading file:%s"%file_name)
#create response object
r = requests.get(link, stream = True)
#download started
with open(file_name, 'wb') as f:
for chunk in r.iter_content(chunk_size = 1024*1024):
if chunk:
f.write(chunk)
print ("%s downloaded!\n"%file_name)
print ("All videos downloaded!")
return
if __name__ == "__main__":
#getting all video links
video_links = get_video_links()
#download all videos
download_video_series(video_links)
Output:

You can find the downloaded videos in your working directory. Know more ways to download videos using python from website.