How to Save Data to MySQL Database- Python Web Scraping
How to Save Data to MySQL Database- Python Web Scraping
Send download link to:
In one of our previous tutorials we saw how to save data to CSV and Excel files. In this tutorial we will learn how we can save data to MYSQL database directly from Python and Jupyter Notebook.
MySQL is an open-source relational database management system (RDBMS). A relational database organizes data into one or more data tables in which data types may be related to each other; these relations help structure the data. SQL is a language programmers use to create, modify and extract data from the relational database, as well as control user access to the database.
To download and setup MySQL db please go to website https://www.mysql.com/downloads/ and follow the instruction.
Also if you are not comfortable with writing SQL query in command line to work with MySQL we recommend you to use Navicat software. Using this you can easily view your database, tables, create new db, tables etc. You can download it here https://www.navicat.com/en/download/navicat-for-mysql.
Once Navicat is installed open it and create a connection to MySQL db by clicking on connection:
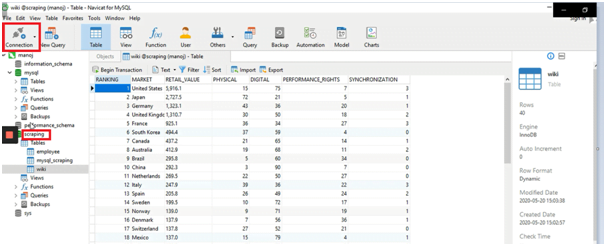
It will ask for name for the connection and a username and password. Notedown the username and password as we will need it in python code. Once a connection is established, create a database and name it “scraping” as highlighted above. Now your database is ready and you can start creating tables and storing data into it.
First let’s go to the webpage and inspect the data we want to scrape:

We want to grab the data in IFPI 2017 Data table, which is a tabular data. As we can see the name of columns is under theadtag and rest of the data is under tbody tag.So using these two tags and writing for loop we can scrap the data.
We will use pymysql module to connect with MySQL using Python.
Below is the detailed code for scraping and saving data to Database. For detailed explanation watch the video:
import bs4
import urllib.request
from urllib.request import urlopen
from bs4 import BeautifulSoup as soup
#Go to webpage and scrape data
html = urlopen('https://en.wikipedia.org/wiki/List_of_largest_recorded_music_markets')
bsobj = soup(html.read())
tbody = bsobj('table',{'class':'wikitableplainrowheaders sortable'})[0].findAll('tr')
xl = []
for row in tbody:
cols = row.findChildren(recursive = False)
cols = tuple(element.text.strip().replace('%','') for element in cols)
xl.append(cols)
xl = xl[1:-1]
#install pymysql module to connect with MySQL Database
pip install pymysql
import pymysql
# Store credantials in file my.propertiesans use Config parser to read from it
import configparser
config = configparser.RawConfigParser()
config.read(filenames = 'my.properties')
print(config.sections())
h = config.get('mysql','host')
u = config.get('mysql','user')
p = config.get('mysql','password')
db = config.get('mysql','db')
# Open database connection
scrap_db = pymysql.connect(h,u,p,db)
# prepare a cursor object using cursor() method
cursor = scrap_db.cursor()
# Drop table if it already exist using execute() method.
cursor.execute("DROP TABLE IF EXISTS WIKI2 ")
# Create table as per requirement
sql = """CREATE TABLE WIKI2 (
RANKINGINT,
MARKETCHAR(50),
RETAIL_VALUECHAR(20),
PHYSICALINT,
DIGITALINT,
PERFORMANCE_RIGHTSINT,
SYNCHRONIZATIONINT
)"""
cursor.execute(sql)
#Save data to the table
scrap_db = pymysql.connect(h,u,p,db)
mySql_insert_query = """INSERT INTO WIKI2 (RANKING, MARKET, RETAIL_VALUE, PHYSICAL,DIGITAL,PERFORMANCE_RIGHTS,SYNCHRONIZATION)
VALUES (%s, %s, %s, %s ,%s, %s, %s) """
records_to_insert = xl
cursor = scrap_db.cursor()
cursor.executemany(mySql_insert_query, records_to_insert)
scrap_db.commit()
print(cursor.rowcount, "Record inserted successfully into WIKI2 table")
# disconnect from server
scrap_db.close()
Hope you enjoyed our tutorial to save data in to MySQL database. We have years of experience in data scraping services and make this tutorial series for learning purpose. In case of any doubt contact us we are ready to serve you.