How to Scrape Multiple Pages from Pagination using Python?
In this tutorial we will see how to scrape data from multiple pages of a website. This is one of the most common tasks in web scraping.
When we search for a product on any ecommerce website like Amazon, the results usually run into hundreds of pages. This process of having multiple pages is called Pagination.
Usually the HTML structure of all these pages remain the same, and we can create our code for first page and then find a way to go to multiple pages and use the same code in a loop on all those pages to grab data.
Generally when a website runs into multiple pages it usually add some extra elements into its URL and keep rest of the URL same. We have to now focus on the structure of the URL, and the changes that occurs when we go from page to page. A simple way to do is go to first page copy the url then go to second page and compare both urls to see the difference.

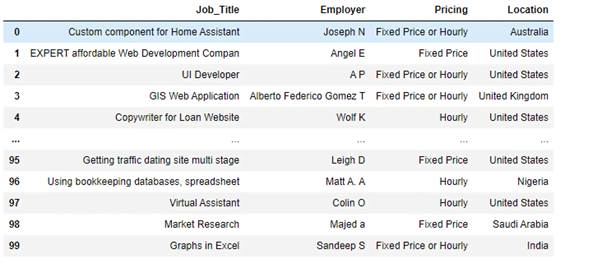
In this tutorial we are going to scrape data from https://www.guru.com/. It is a freelancing website. On this website when we search for Data Science Jobs and we get the following URL: https://www.guru.com/d/jobs/skill/data-science/.
The URL contains my search word. Now there are 216 results running into 11 pages:


If we go to second page the URL changes to https://www.guru.com/d/jobs/skill/data-science/pg/2/. So /pg/2 gets added in the URL. This is how Guru.com changes its pages.
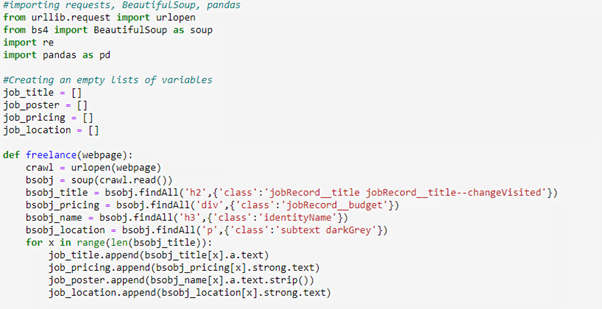
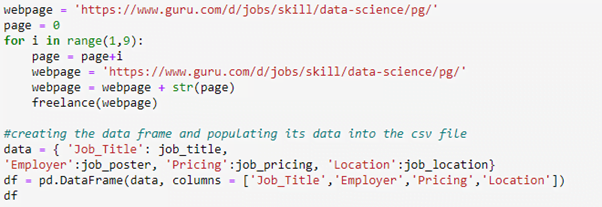
Now that we know this we can create a variable link and then write a loop to go to all 11 pages and scrape data. Below is the complete code for it. Watch the video for detailed explanation:
Output: