How to Use Socks Proxy with Request Module in Python
How to Use Socks Proxy with Request Module in Python
Send download link to:
In one of our previous tutorial we learned about HTTP proxy. In this tutorial we will see another type of proxy called SOCKS.
A proxy or proxy server is a computer that sits between you and the web server. It acts as a gateway between a local network and the internet.
A proxy server works by intercepting connections between sender and receiver. All incoming data enters through one port and is forwarded to the rest of the network via another port.
Aside from traffic forwarding, proxy servers provide security by hiding the actual IP address of a server.
SOCKS, which stands for Socket Secure, is a network protocol that facilitates communication with servers through a firewall by routing network traffic to the actual server on behalf of a client. SOCKS is designed to route any type of traffic generated by any protocol or program.
In addition to basic HTTP proxies, Requests also supports proxies using the SOCKS protocol. This is an optional feature that requires that additional third-party libraries be installed before use.
You can get the dependencies for this feature from pip:
pip install requests[socks]
Using the scheme socks5 causes the DNS resolution to happen on the client, rather than on the proxy server. This is in line with curl, which uses the scheme to decide whether to do the DNS resolution on the client or proxy. If you want to resolve the domains on the proxy server, use socks5h as the scheme.
How to send requests through a SOCKS Proxy in Python 3 using Requests
There are many websites dedicated to providing free proxies on the internet. One such site is https://www.socks-proxy.net/. Go to the website and select a working proxy and put it in the below code.
pip install requests[socks]
import requests
url = 'https://httpbin.org/ip'
proxies = {
"http":'socks5://174.76.35.15:36163',
"https":'socks5://174.76.35.15:36163'
}
response = requests.get(url,proxies=proxies)
Rotating Requests through a pool of Proxies in Python 3
Rotating proxies is good habit to avoid getting blocked from website as most websites actively try to block scrapers.
We’ll gather a list of some active proxies from https://www.socks-proxy.net/. To do that we will scrape this website. You can also use private proxies if you have access to them.
As we can see from below image the IP addresses are in a form of table and we need to get them from first column:
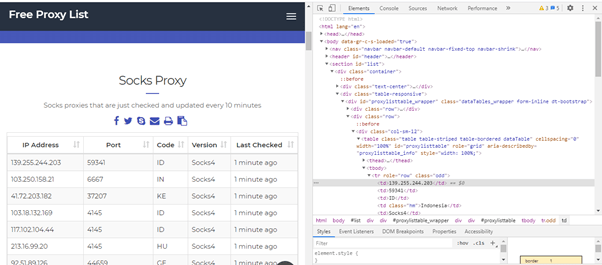
import requests
from bs4 import BeautifulSoup as soup
url = 'https://www.socks-proxy.net/'
response = requests.get(url)
bsobj = soup(response.content)
proxies= set()
for ip in bsobj.findAll('table')[0].findAll('tbody')[0].findAll('tr'):
cols = ip.findChildren(recursive = False)
cols = [element.text.strip() for element in cols]
#print(cols)
proxy = ':'.join([cols[0],cols[1]])
proxy = 'socks4://'+proxy
proxies.add(proxy)
print(proxy)
Output:
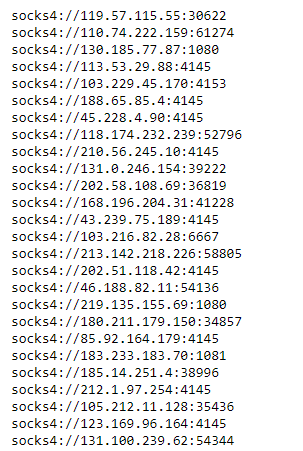
Now that we have the list of Proxy IP Addresses in a variable proxies, we’ll go ahead and rotate it using a Round Robin method and send get request.
import requests
from itertools import cycle
#If you are copy pasting proxy ips, put in the list below
#proxies = ['121.129.127.209:80', '124.41.215.238:45169', '185.93.3.123:8080', '194.182.64.67:3128', '106.0.38.174:8080', '163.172.175.210:3128', '13.92.196.150:8080']
proxy_pool = cycle(proxies)
url = 'https://httpbin.org/ip'
for i in range(1,10):
#Get a proxy from the pool
proxy = next(proxy_pool)
print("Request #%d"%i)
try:
response = requests.get(url,proxies={"http": proxy, "https": proxy})
print(response.json())
except:
#Most free proxies will often get connection errors. You will have retry the entire request using another proxy to work.
#We will just skip retries as its beyond the scope of this tutorial and we are only downloading a single url
print("Skipping. Connnection error")
Output:
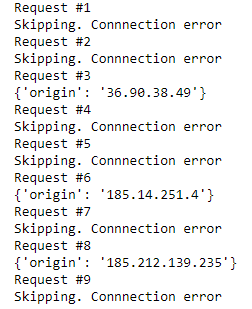
As you can see only 3 of our request were successful that is because most free proxies expire quickly. If you need to scrape large amount of data it is recommended to use paid proxies.