How to Use HTTP Proxy with Request Module in Python
How to Use HTTP Proxy with Request Module in Python
Send download link to:
Using effective HTTP proxy is essential for any web scraping project. When scraping the websites to grab large amount of data, using proxies is an absolute must.
A common problem faced by web scrapers is getting blocked by websites while scraping them. There are many techniques to prevent getting blocked, like
- Rotating IP addresses
- Using Proxies
Using proxies and rotating IP addresses in combination with rotating user agents can help you get scrapers past most of the anti-scraping measures and prevent being detected as a scraper.
The concept of rotating IP addresses while web scraping is simple – you can make it look to the website that you are not a single ‘bot’ or a person accessing the website, but multiple ‘real’ users accessing the website from multiple locations. If you do it right, the chances of getting blocked are minimal.
What is a proxy?
A proxy is a third party server that enables you to route your request through their servers and use their IP address in the process. When using a proxy, the website to which you are making the request to, no longer sees your device’s IP address but the IP address of the proxy, giving you the ability to scrape the web anonymously and avoid getting blocked.
How to Send Requests Through a Proxy in Python 3 using Requests
There are many websites dedicated to providing free proxies on the internet. One such site is https://free-proxy-list.net/. Let’s go there and pick a proxy that supports https. Pick any working proxy from this website and put in below code. Keep in mind that since these proxies are free, it expires quickly and may not support to run below code multiple times.
import requests
url = 'https://httpbin.org/ip'
proxies = {
"http":'http://203.190.46.62:8080',
"https":'https://111.68.26.237:8080'
}
response = requests.get(url,proxies=proxies)
print(response.json())
Output:
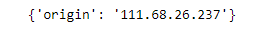
Rotating Requests Through a Pool of Proxies in Python 3
We’ll gather a list of some active proxies from https://free-proxy-list.net/. You can also use private proxies if you have access to them.
import requests
from lxml.html import fromstring
def get_proxies():
url = 'https://free-proxy-list.net/'
response = requests.get(url)
parser = fromstring(response.text)
proxies = set()
for i in parser.xpath('//tbody/tr')[:100]:
if i.xpath('.//td[7][contains(text(),"yes")]'):
#Grabbing IP and corresponding PORT
proxy = ":".join([i.xpath('.//td[1]/text()')[0], i.xpath('.//td[2]/text()')[0]])
proxies.add(proxy)
return proxies
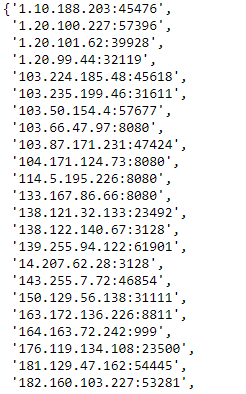
get_proxies()
output:
proxies = get_proxies()
Now that we have the list of HTTP Proxy IP Addresses in variable proxies, we’ll go ahead and rotate it using a Round Robin method
import requests
from itertools import cycle
#If you are copy pasting proxy ips, put in the list below
#proxies = ['121.129.127.209:80', '124.41.215.238:45169', '185.93.3.123:8080', '194.182.64.67:3128', '106.0.38.174:8080', '163.172.175.210:3128', '13.92.196.150:8080']
proxies = get_proxies()
proxy_pool = cycle(proxies)
url = 'https://httpbin.org/ip'
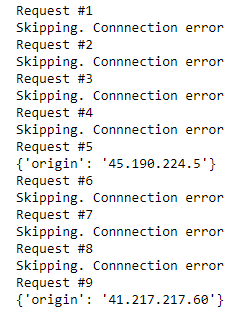
for i in range(1,10):
#Get a proxy from the pool
proxy = next(proxy_pool)
print("Request #%d"%i)
try:
response = requests.get(url,proxies={"http": proxy, "https": proxy})
print(response.json())
except:
#Most free proxies will often get connection errors. You will have retry the entire request using another proxy to work.
#We will just skip retries as its beyond the scope of this tutorial and we are only downloading a single url
print("Skipping. Connnection error")
Output: