How to Crawl Data from Internal and External Links
How to Crawl Data from Internal and External Links
Send download link to:
In this tutorial we will see how to crawl data across internet and follow internal and external links.
Till now we have seen how to scrape data from a single page, but that not usually how we need to extract data. Many times, we need to go to multiple pages grab some data from there and then follow the links on those pages to grab more data. That’s what Web crawling is going to a page then finding more links on that page, follow them and crawl data.
But first we need to learn URL parsing which will help the program to decide if it is an internal links or external link.
URL Parsing
The URL parsing functions focus on splitting a URL string into its components, or on combining URL components into a URL string.
urllib.parse.urlparse(urlstring, scheme=”, allow_fragments=True)
Parse a URL into six components, returning a 6-item named tuple.
This corresponds to the general structure of a URL: scheme://netloc/path;parameters?query#fragment.
Each tuple item is a string, possibly empty. The components are not broken up in smaller parts (for example, the network location is a single string), and % escapes are not expanded. The delimiters as shown above are not part of the result, except for a leading slash in the path component, which is retained if present. For example:
from urllib.parse import urlparse o = urlparse('http://www.cwi.nl:80/%7Eguido/Python.html')
ParseResult(scheme='http', netloc='www.cwi.nl:80', path='/%7Eguido/Python.html', params='', query='', fragment='')
o.scheme
'http'
o.port
80
o.geturl()
'http://www.cwi.nl:80/%7Eguido/Python.html'
Following the syntax specifications in RFC 1808, urlparse recognizes a netloc only if it is properly introduced by ‘://’. Otherwise the input is presumed to be a relative URL and thus to start with a path component.
from urllib.parse import urlparse urlparse('//www.cwi.nl:80/%7Eguido/Python.html') ParseResult(scheme='', netloc='www.cwi.nl:80', path='/%7Eguido/Python.html', params='', query='', fragment='') urlparse('www.cwi.nl/%7Eguido/Python.html') ParseResult(scheme='', netloc='', path='www.cwi.nl/%7Eguido/Python.html', params='', query='', fragment='') urlparse('help/Python.html') ParseResult(scheme='', netloc='', path='help/Python.html', params='', query='', fragment='')
Once we have parsed the URL program will decide if its an internal link or external based on the initial url we passed:
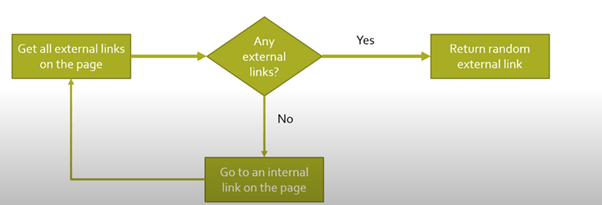
Below is the complete code:
from urllib.request import urlopen
from urllib.parse import urlparse
from bs4 import BeautifulSoup as soup
import re
import datetime
import random
pages = set()
random.seed(datetime.datetime.now())
def getintlinks(bsobj,includeurl):
includeurl = urlparse(includeurl).scheme + "://" + urlparse(includeurl).netloc
internalLinks = []
for links in bsobj.findAll('a', href = re.compile("^(/|.*"+includeurl+")")):
if links.attrs['href'] is not None:
if links.attrs['href'] not in internalLinks:
if (links.attrs['href'].startswith("/")):
internalLinks.append(includeurl+links.attrs['href'])
else:
internalLinks.append(links.attrs['href'])
return internalLinks
def getextlinks(bsobj,excluderl):
externalLinks = []
for links in bsobj.findAll('a',href = re.compile("^(http|www)((?!"+excluderl+").)*$")):
if links.attrs['href'] is not None:
if links.attrs['href'] not in externalLinks:
externalLinks.append(links.attrs['href'])
return externalLinks
def getrandomextlinks(startingpage):
html = urlopen(startingpage)
bsobj = soup(html,'lxml')
externalLinks = getextlinks(bsobj, urlparse(startingpage).netloc)
if len(externalLinks) == 0:
print('No External Links, looking around the site for one')
domain = urlparse(startingpage).scheme + '://'+ urlparse(startingpage).netloc
internalLinks = getintlinks(bsobj,domain)
return getrandomextlinks(internalLinks[random.randint(0,len(internalLinks)-1)])
else:
return externalLinks[random.randint(0,len(externalLinks)-1)]
def followextonly(startingsite):
externalLinks = getrandomextlinks(startingsite)
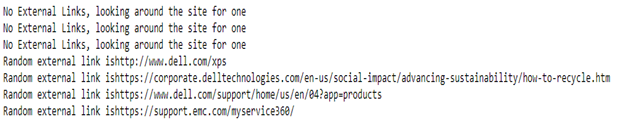
print('Random external link is' + externalLinks)
followextonly(externalLinks)
followextonly ('https://unsplash.com/s/photos/pic')
Output:
Learn more about python scraping using our Python web scraping Tutorials.